2. Métodos para el Cálculo de Autovalores#
2.1. Contenido#
Semana 1: Métodos iterativos para el cálculo de autovectores dominantes.
- Método de la potencia.
- Método de la potencia inversa (shift & invert).
- Empezamos importando los módulos necesarios y definiendo la matriz de la que queremos calcular los autovalores.
import numpy as np
import scipy.linalg as sp
from tabulate import tabulate
v = np.random.rand(4)
A = np.reshape(v,(1,4)) # Matriz de 1 fila y 4 columnas (Vector fila)
B = np.reshape(v,(4,1)) # Matriz de 4 filas y 1 columna (Vector columna)
Matriz = np.matmul(B,A) # Matriz simétrica, el elemento (i,j) es v(i)*V(j)
#print(tabulate(Matriz))
- A continuación definimos algunas funciones útiles que vamos a usar
def norm2(v):
return np.sqrt(sum(v*v))
2.2. Métodos iterativos para el cálculo de un autovector.#
Vamos a hacer una serie de suposiciones necesarias para garantizar que estos métodos funcionan adecuadamente. En primer lugar consideramos una matriz \(A \in \mathbb M_{n \times n}(\mathbb R)\) no singular, cuadrada, formada por coeficientes reales y diagonalizable.
En segundo lugar vamos a considerar que los autovalores cumplen:
Es decir, que tenemos un autovalor \(\lambda_1\) que llamaremos dominante, que es mayor en valor absoluto que el resto. Además vamos a considerar que la multiplicidad geométrica (no solo la algebraica) es uno. Eso implica que sólo tiene asociado un autovector, que llamaremos autovector dominante.
Bajo estas condiciones, para calcular el \(\textbf{autopar}\) (autovalor y autovector asociado) podemos utilizar el método de la potencia.
2.2.1. Método de la potencia.#
Sea \(\mathbf{x} \in \mathbb R^n\), entonces, por ser \(A\) diagonalizable, existe una base del espacio vectorial \(\mathbb R^n\) formada por autovectores de \(A\), \(B_v = \{\vec{v}_1, \vec{v}_2, \vec{v}_3, \dots, \vec{v}_n \}\) con \(A \vec{v}_i = \lambda_i \vec{v}_i\), de modo que:
Entonces:
Considerando que \(|\lambda_1| \gt |\lambda_2| \ge \dots \ge |\lambda_n|\) podemos reescribir:
Multiplicando de forma iterativa por la matriz \(A\) obtenemos el siguiente proceso iterativo:
\(\mathbf{x}^1 = A\mathbf{x}\);
\(\mathbf{x}^2 = A\mathbf{x}^1 = A^2\mathbf{x}\);
…
\(\mathbf{x}^p=A^p\mathbf{x} = \left(\lambda_{1}\right)^{p} \left( c_1\vec{v}_1 + c_2\left(\frac{\lambda_2}{\lambda_1}\right)^p\vec{v}_2 + \dots + c_n\left(\frac{\lambda_n}{\lambda_1}\right)^p\vec{v}_n \right)\)
Como \(|\lambda_1|\gt |\lambda_i| \quad \forall i=2,\cdots,n\) los cocientes de autovalores se hacen cada vez más pequeños a medida que aumenta el exponente \(p\). Por ello se espera que en el límite:
Es decir, que, a medida que multiplicamos sucesivamente por la matriz \(A\), la operación nos lleve en la dirección del autovalor dominante. Este resultado teórico tiene algunos inconvenientes a la hora de implementarlo numéricamente. Uno de los más típicos se debe a la inestabilidad numérica causada por el aumento exponencial de \(\left(\lambda_{1}\right)^{p}\) y el decaimiento tambien exponencial de \(\left(\dfrac{\lambda_i}{\lambda_1}\right)^p\). Este inconveniente se puede solucionar facilmente normalizando el resultado de \(\mathbf{x}^j=A\mathbf{x}^{j-1}\) en cada iteración.
El método de la potencia converge al autovector dominante normalizado \(v_1\), para calcular el autovalor correspondiente podemos emplear el cociente de Rayleigh:
Veamos como implementarlo:
def potencia(A):
if A.shape[0]!=A.shape[1]: return None #Comprobamos que la matriz sea cuadrada
n = A.shape[0]
x = np.random.rand(n) # Tomamos un vector aleatorio para empezar a iterar
x = x/norm2(x) # Normalizamos dicho vector
convergencia = False
while not convergencia: # Proceso iterativo hasta la convergencia
x1 = np.matmul(A,x)
x1 = x1/norm2(x1)
if norm2(x1-x)<0.0000001: # Convergencia alcanzada en el autovector
convergencia = True
eigenvalue = np.dot(x1,np.matmul(A,x1))
x = x1.copy()
return eigenvalue,x1 # Devolvemos como resultado el autovalor y autovector dominantes
Pongamos un ejemplo sencillo para ver como funciona.
Hemos escogido una matriz real, simétrica y por tanto con todos los autovalores reales. Los autovalores de esta matriz son: \(\lambda_1 = 2.74; \lambda_2 = -2.35; \lambda_3 = -1.4\). Lo podemos comprobar mediante la funcion eigvals() del módulo scipy.linalg que nos devuelve los autovalores de una matriz
A = np.array([[1.,1.,2.],[1.,-1.,1.],[2.,1.,-1.]])
print(sp.eigvals(A))
[ 2.74482608+0.j -1.39593186+0.j -2.34889422+0.j]
Apliquemos el método de la potencia para calcular el par dominante.
eigval,eigvec = potencia(A)
print(f'Autovalor dominante: {eigval}, autovector: {eigvec}')
Autovalor dominante: 2.7448260776819158, autovector: [0.78579649 0.34661858 0.51222986]
2.2.1.1. Criterio de Convergencia.#
El criterio de parada escogido en la implementación inicial ha sido: $\(||\mathbf{x}^j-\mathbf{x}^{j-1}|| \lt \varepsilon\)$
Es decir que el módulo de la diferencia entre dos aproximaciones consecutivas del autovector sea menor que un valor pequeño \(\varepsilon\).
Este criterio da problemas si el autovalor dominante es negativo. En cada iteración el vector cambiará de sentido (manteniendo la dirección) lo que hará que no se cumpla el criterio de convergencia. Para comprobarlo basta que cambies el signo del elemento \(A_{1,1}\).
Ahora el autovalor dominante es \(\lambda_1 = -3\) y el proceso iterativo devuelve:
-
...
- Iteración: 23669
x1 = (-7.07106781e-01, 3.70074342e-17, 7.07106781e-01)
- Iteración: 23670
x1 = ( 7.07106781e-01, 3.70074342e-17, -7.07106781e-01)
- Iteración: 23671
x1 = (-7.07106781e-01, 3.70074342e-17, 7.07106781e-01)
- Iteración: 23672
x1 = ( 7.07106781e-01, 3.70074342e-17, -7.07106781e-01)
…
Se puede corregir usando como criterio que el coseno del ángulo que forman las aproximaciones sucesivas sea 1 o -1.
Pero, por lo general, para evitar ese problema se suele utilizar el comportamiento de las aproximaciones del autovalor dominante como condición de parada.
def potencia(A):
if A.shape[0]!=A.shape[1]: return None # Comprobamos que la matriz sea cuadrada
n = A.shape[0]
x = np.random.rand(n) # Tomamos un vector aleatorio para empezar a iterar
x = x/norm2(x) # Normalizamos dicho vector
eigvalue = np.dot(x,np.matmul(A,x)) # Aproximación inicial del autovalor
convergencia = False
while not convergencia:
x1 = np.matmul(A,x) # Nueva aproximación a partir del producto matriz-vector
x1 = x1/norm2(x1)
eigvalue1 = np.dot(x1,np.matmul(A,x1))
if abs(eigvalue1-eigvalue)<0.0001: # Criterio de parada basado en la convergencia del autovalor
convergencia = True
x = x1.copy()
eigvalue = eigvalue1
return eigvalue1,x1 # Devolvemos como resultado el autovalor y autovector dominantes
# Problemas de convergencia
A = np.array([[-1.,1.,2.],[1.,-1.,1.],[2.,1.,-1.]])
eigval,eigvec = potencia(A)
print(f'Autovalor dominante: {eigval}, autovector: {eigvec}')
Autovalor dominante: -2.999979400362885, autovector: [-7.05534607e-01 1.32842847e-04 7.08675456e-01]
2.2.2. Método de la potencia inversa. (shift & invert)#
Una pequeña variación del método de la potencia nos va a servir para calcular el autovalor más proximo a cero en valor absoluto y su autovector asociado. Para ello basta recordar de Algebra Lineal que si \( \lambda \) es un autovalor de la matriz \( A \) entonces \( \dfrac{1}{\lambda} \) es autovalor de la inversa \( A^{-1} \). Veamoslo:
Sea \( A \in \mathbb M_{n \times n}(\mathbb R) \) matriz cuadrada, no singular de números reales y sean: \( \left( \lambda, \vec{v} \right) \) un par autovalor-autovector de dicha matriz. Entonces:
y por tanto \( \dfrac{1}{\lambda} \) es autovalor de la matriz inversa \( A^{-1} \) asociado al mismo autovector \( \vec{v} \).
Como además, si \( |\lambda_1| \gt |\lambda_2| \ge |\lambda_3| \ge \dots \gt |\lambda_n| \) se cumple que \( |\dfrac{1}{\lambda_1}| \lt |\dfrac{1}{\lambda_2}| \le |\dfrac{1}{\lambda_3}| \le \dots \lt |\dfrac{1}{\lambda_n}| \) Basta repetir el proceso iterativo del método de la potencia con \( A^{-1} \) en lugar de \( A \) para hallar el autovector dominante de \( A^{-1} \) que será el asociado al autovector dominante \( \dfrac{1}{\lambda_n} \).
Habremos encontrado el autovector de \( A \) asociado al autovalor \( \lambda_n \), el más proximo a 0.
A la hora de implementar este método tendremos en cuenta que el cálculo de la inversa es costoso y por tanto en lugar de iterar \( \mathbf{x}^j=A^{-1}\mathbf{x}^{j-1} \) haremos \( A\mathbf{x}^j=\mathbf{x}^{j-1} \) lo que supone resolver un sistema lineal en cada paso.
No solo eso, como la matriz \( A \) del sistema lineal permanece constante en todas las iteraciones vamos a utilizar lo aprendido en el tema anterior y separaremos la resolución en 3 etapas. La factorización LU se realiza una única vez fuera del bucle de las iteraciones mientras que en cada paso solo tenemos que resolver los dos sistemas triangulares.
def potencia_inversa(A):
if A.shape[0]!=A.shape[1]: return None # Comprobamos que la matriz sea cuadrada
n = A.shape[0]
x = np.random.rand(n) # Tomamos un vector aleatorio para empezar a iterar
x = x/norm2(x) # Normalizamos dicho vector
eigvalue = np.dot(x,np.matmul(A,x)) # Aproximación inicial del autovalor usando A
convergencia = False
# FACTORIZACION LU de A
P,L,U = sp.lu(A)
while not convergencia:
#Resuelvo los dos sistemas lineales triangulares
y = sp.solve_triangular(L, np.matmul(P,x), lower=True)
x1 = sp.solve_triangular(U, y, lower=False)
x1 = x1/norm2(x1)
eigvalue1 = np.dot(x1,np.matmul(A,x1)) # Aproximación del autovalor asociado al autovector menos dominante usando A
if abs(eigvalue1-eigvalue)<0.0001: # Criterio de parada basado en la convergencia del autovalor
convergencia = True
x = x1.copy()
eigvalue = eigvalue1
return eigvalue1,x1 # Devolvemos como resultado el autovalor más próximo a 0 y su autovector
Vamos a probarlo con la matriz \(A\) cuyos autovalores eran: \(\lambda_1 = 2.74; \lambda_2 = -2.35; \lambda_3 = -1.4\).
A = np.array([[1.,1.,2.],[1.,-1.,1.],[2.,1.,-1.]])
eigval,eigvec = potencia_inversa(A)
print(f'Autovalor más próximo a 0: {eigval}, autovector asociado: {eigvec}')
Autovalor más próximo a 0: -1.3959291294825258, autovector asociado: [ 0.46550183 -0.87735905 -0.11640082]
2.2.2.1. Método de la potencia inversa con shift.#
Una vez que hemos usado la potencia sobre la matriz inversa para calcular el autovalor más proximo a cero podemos modificarlo para calcular el autovalor más próximo a un valor dado. Basta comprobar que si \(\mu\) es un autovalor de \(A\) y \(\vec{v}\) su autovector asociado, entonces la matriz \(A-\alpha I\) tiene como autovalor \(\mu-\alpha\) asociado al mismo autovector \(\vec{v}\). $\( \left( A-\alpha I\right )\vec{v}= A\vec{v}-\alpha \vec{v} =\mu \vec{v} -\alpha \vec{v} = \left( \mu-\alpha \right)\vec{v}\)$
Por tanto si aplicamos el metodo de la potencia inversa a la matriz \( A-\beta I\) hallaremos el autovector de la matriz \(A\) cuyo autovalor está más proximo a \(\beta\).
Al igual que antes la manera eficiente de implementarlo es a través de la resolución de un sistema lineal en cada paso separando la descomposición LU (única) de la resolución de los sistemas triangulares.
def potencia_inversa_shift(A,beta):
if A.shape[0]!=A.shape[1]: return None # Comprobamos que la matriz sea cuadrada
n = A.shape[0]
B = A-beta*np.eye(n)
x = np.random.rand(n) # Tomamos un vector aleatorio para empezar a iterar
x = x/norm2(x) # Normalizamos dicho vector
eigvalue = np.dot(x,np.matmul(A,x)) # Aproximación inicial del autovalor usando A
convergencia = False
# FACTORIZACION LU de B = A-betaI
P,L,U = sp.lu(B)
while not convergencia:
#Resuelvo los dos sistemas lineales triangulares
y = sp.solve_triangular(L, np.matmul(P,x), lower=True)
x1 = sp.solve_triangular(U, y, lower=False)
x1 = x1/norm2(x1)
eigvalue1 = np.dot(x1,np.matmul(A,x1)) # Aproximación del autovalor asociado al autovector menos dominante usando A
if abs(eigvalue1-eigvalue)<0.0001: # Criterio de parada basado en la convergencia del autovalor
convergencia = True
x = x1.copy()
eigvalue = eigvalue1
return eigvalue1,x1 # Devolvemos como resultado el autovalor más próximo a 0 y su autovector
A = np.array([[1.,1.,2.],[1.,-1.,1.],[2.,1.,-1.]])
eigval,eigvec = potencia_inversa_shift(A,-2)
print(f'Autovalor más próximo a -2: {eigval}, autovector asociado: {eigvec}')
Autovalor más próximo a -2: -2.3488642433349067, autovector asociado: [ 0.40828871 0.3313773 -0.85058181]
2.3. Métodos para el cálculo del espectro completo de autovalores.#
2.4. Introducción.#
Vamos a centrarnos unicamente en el cálculo del espectro para matrices reales, simétricas y con autovalores distintos. Aunque parece una restricción muy fuerte existen numerosos problemas interesantes con esas características. Por ejemplo el PCA Principal Component Analysis, utilizado en problemas de reducción de dimensionalidad para compresión de información o reconocimiento de imágenes, precisa el calculo del espectro completo de la matriz de covarianza de un conjunto de datos siendo dicha matriz simétrica y definida positiva.
La simetría de la matriz nos permite asegurar que los autovalores van a ser reales. Además, al pedir que esos autovalores sean distintos entre sí podemos garantizar que los autovectores asociados sean ortogonales entre si.
Podemos demostrar esto último facilmente: Operando podemos comprobar que si \(A\) es una matriz real:
Si suponemos además que \(\vec{x}\) e \(\vec{y}\) son autovectores asociados a los autovalores distintos \(\lambda\) y \(\beta\) respectivamente:
Como \(A\) es simétrica \(A=A^T\), entonces:
Hemos probado que:
Como \(\lambda \ne \beta\) para que se cumpla es necesario que \(\left<\vec{x},\vec{y}\right> = 0\). Es decir que \(\vec{x}\) e \(\vec{y}\) sean ortogonales entre si.
En ese contexto intentaremos extender el método de la potencia para calcular el espectro completo de la matriz. Y veremos que podemos extender el método de la potencia de modo inteligente en este caso sencillo como hace el método de Iteración Simultanea. E iremos un paso más allá, aprovechando la idea que nos da la Iteración Simultánea para explicar uno de los métodos más utilizado para el cálculo del espectro completo, el algoritmo QR. Este algoritmo es equivalente a la Iteración Simultánea para matrices reales, simétricas con autovalores diferentes pero se puede utilizar también para el cálculo de autovalores y autovectores de matrices no simétricas o complejas. En cualquier caso estas variaciones van mucho más allá de los objetivos de este curso donde solo se pretende mostrar las versiones más sencillas de los algoritmos.
Antes de entrar en los métodos de cálculo de autovalores nos vamos a detener en una herramienta que va a ser de gran utilidad: la factorización QR de una matriz.
2.4.1. Descomposición QR. QR-decomposition.#
La descomposición QR de una matriz \(A \in \mathbb M_{n \times n}(\mathbb R)\) es una factorización de la forma: $\(A = QR\)\( donde \)Q\( es una matriz ortogonal y \)R\( una matriz triangular superior. Recordad que una matriz ortogonal cumple: \)Q^TQ = I\(, es decir, su inversa es su traspuesta. Además, como consecuencia directa de que \)Q^TQ = I\( las columnas de \)Q$ son vectores ortogonales.
Geometricamente, si las columnas de \(A\) son una base de \(\mathbb R^n\) entonces las columnas de \(Q\) son una base ortogonal de \(\mathbb R^n\) y la matriz de cambio de base sería \(R\). Existen diferentes maneras de calcular la descomposición QR de una matriz \(A\). Nos vamos a centrar en la que habéis visto en Álgebra que es el método de Gram-Schmidt. Este método tiene gran importancia académica pero no es el habitualmente usado por ser numericamente inestable. Esto quiere decir que los errores de precisión pueden provocar que los vectores que devuelve no sean ortogonales entre sí. Otros métodos con mejor comportamiento numérico son las transformaciones Householder o las rotaciones de Givens.
El método de Gram-Schmidt parte de un conjunto de vectores linealmente independientes entre si. El primero es normalizado antes de añadirlo a la nueva base ortogonal. A partir de aquí a cada vector del conjunto original se le resta su proyección ortogonal sobre los ya incluidos en la nueva base antes de añadirlo. Se puede normalizar cada vector para obtener una base ortonormal.
con
Geometricamente:

Si partimos de las columnas de la matriz \(A\):
Entonces:
En esta nueva base, al ser ortonormal, se cumple:
Que matricialmente:
Se puede codificar facilmente en Python:
def QR_decomposition(A):
Q = np.zeros_like(A) # Las columnas de Q guardaran la base ortonormal
R = np.zeros_like(A)
for j in range(A.shape[1]):
v = A[:,j]
for i in range(j): # Iteramos sobre los vectores ya incluidos en la base ortonormal
R[i,j] = np.dot(A[:,j],Q[:,i])
v = v - R[i,j]*Q[:,i] # Restamos la proyección sobre el vector Q[:,i] ya calculado
Q[:,j] = v/norm2(v) # Normalizamos antes de añadirlo
R[j,j] = np.dot(v,Q[:,j])
return Q,R
Veamos como se comporta:
# Matriz A
A = np.array([[1.,-1., -2.],[4., 0., 3.],[-1., 1., 1.]])
print(f'A= \n {tabulate(A)}')
Q,R = QR_decomposition(A)
print(f'Q= \n {tabulate(Q)}')
print(f'R= \n {tabulate(R)}')
print(f'QR = \n {tabulate(Q@R)}')
A=
-- -- --
1 -1 -2
4 0 3
-1 1 1
-- -- --
Q=
--------- --------- ------------
0.235702 -0.666667 -0.707107
0.942809 0.333333 -9.42055e-16
-0.235702 0.666667 -0.707107
--------- --------- ------------
R=
------- --------- --------
4.24264 -0.471405 2.12132
0 1.33333 3
0 0 0.707107
------- --------- --------
QR =
-- ------------ --
1 -1 -2
4 8.63507e-17 3
-1 1 1
-- ------------ --
Tambiem podemos utilizar la función de numpy ** np.linalg.qr()** que llama a una subrutina de LAPACK que emplea transformaciones de Householder.
Q,R = np.linalg.qr(A)
print(f'Q= \n {tabulate(Q)}')
print(f'R= \n {tabulate(R)}')
print(f'QR = \n {tabulate(Q@R)}')
Q=
--------- --------- --------
-0.235702 0.666667 0.707107
-0.942809 -0.333333 0
0.235702 -0.666667 0.707107
--------- --------- --------
R=
-------- --------- ---------
-4.24264 0.471405 -2.12132
0 -1.33333 -3
0 0 -0.707107
-------- --------- ---------
QR =
-- ----------- --
1 -1 -2
4 6.7847e-17 3
-1 1 1
-- ----------- --
2.5. Método de la Iteración Simultánea. Simultaneous Iteration.#
Como hemos dicho antes nos vamos a centrar en el cálculo de autovalores y autovectores de matrices reales, simétricas y con autovalores distintos. El primer método que vamos a ver es el de la Iteración Simultánea que es una extensión inteligente de los métodos de la potencia a este caso particular.
Los métodos de la potencia nos permiten calcular un único autovalor-autovector cada vez. Si aplicamos el método de la potencia a un conjunto de vectores linealmente independientes entre sí: \( V = \{\vec{v}_1, \vec{v}_2, \vec{v}_3, \dots, \vec{v}_n \} \), despues de suficientes iteraciones, todos los vectores \( \{ A^{k}\vec{v}_i \} \) habrán convergido al autovector dominante. ¿Hay algún modo de que cada vector converja en un autovector diferente?.
Ahora es cuando entra en juego la descomposición QR y el hecho de que la matriz \( A \) sea simétrica. Recordemos que la simetría nos garantiza que todos los autovalores son reales y, la suposición extra de que los autovalores sean diferentes, nos asegura la ortogonalidad de los autovectores asociados. Si queremos encontrar la base de autovectores ortogonales, en cada paso del método de la potencia, debemos ortogonalizar (ortonormalizar) el conjunto de vectores \( \{ A\vec{v}_i \} \). De esta manera forzamos que las aproximaciones sean ortonormales entre si.
El algoritmo es sencillo y se puede escribir en pocas líneas:
Para calcular los autovalores asociados a cada autovector bastará aplicar el cociente de Rayleigh a cada autovector.
La elección de \(Q^0=I\) garantiza la ortonormalidad en el paso inicial.
def simultaneous_iteration(A):
Q = np.eye(A.shape[0])
eigenvalue = np.zeros(A.shape[1])
for i in range(10000):
Z = np.matmul(A,Q)
Q,R = np.linalg.qr(Z)
# Los autovectores están en las columnas de Q
for i in range(Q.shape[1]):
eigenvalue[i] = np.dot(Q[:,i],np.matmul(A,Q[:,i])) # No hace falta dividir por la norma ya que ||Q_i||=1
return eigenvalue,Q
Veamoslo en un ejemplo sencillo \(3x3\)
# Matriz simetrica
S = np.array([[4.,-14., -12.],[-14., 10., 13.],[-12., 13., 1.]])
print(tabulate(S))
--- --- ---
4 -14 -12
-14 10 13
-12 13 1
--- --- ---
Cuyos autovalores y autovectores asociados, calculados con la función específica de numpy, son:
values, vect = np.linalg.eig(S)
print('Autovalores: ',values)
columna = vect.T
for i,vec in enumerate(columna):
print(f'Autovector {i}: {vec} ')
Autovalores: [31.53568967 -9.64366467 -6.89202501]
Autovector 0: [-0.55567116 0.6635882 0.50087949]
Autovector 1: [ 0.59474589 -0.10370353 0.7971969 ]
Autovector 2: [-0.58095343 -0.74087535 0.3370413 ]
Mediante el método de Iteración Simultánea queda:
values,vect = simultaneous_iteration(S)
print('Autovalores: ',values)
columna = vect.T
for i,vec in enumerate(columna):
print(f'Autovector {i}: {vec} ')
Autovalores: [31.53568967 -9.64366467 -6.89202501]
Autovector 0: [-0.55567116 0.6635882 0.50087949]
Autovector 1: [-0.59474589 0.10370353 -0.7971969 ]
Autovector 2: [-0.58095343 -0.74087535 0.3370413 ]
Recuerda que si \(\vec{v}\) es un autovector asociado a \(\lambda\) también lo es \(-\vec{v}\). \(A(-\vec{v}) = -A\vec{v}= -\lambda \vec{v} = \lambda (-\vec{v})\)
2.6. Algoritmo QR para el cálculo del espectro completo.#
Empezaremos con algunas generalidades del algoritmo y proposiones algebráicas teóricas que nos van a permitir situar el algoritmo QR dentro de un contexto más general. Es decir, aunque nosotros nos vamos a centrar en una matriz con ciertas restricciones, el algoritmo QR es aplicable para un rango de matrices mucho más extenso: no simetricas, con multiplicidad algebraica de los autovalores e incluso con valores complejos.
- Definición 1:
- Proposición 1:
- Definición 2:
- Definición 3 (ya vista):
- Proposición 2:
- Proposición 3:
Toda matriz cuadrada \(A \in \mathbb{C}^{n\times n}\) se puede escribir como \(A = HTH^{-1}\) donde \(H\) es una matriz unitaria y \(T\) es una matriz quasi-triangular. Si \(A \in \mathbb{R}^{n\times n}\) entonces la factorización se convierte en \(A = QTQ^{-1}\) con \(Q\) matriz ortogonal. En ambos casos a esta factorización se la conoce como descomposición de Schur o Schur decomposition.
Como \(A\) y \(T\) son semejantes (Proposición 1) tienen los mismos autovalores. Si todos los autovalores de \(A\) son reales la matriz \(T\) será triangular y los autovalores estarán en la diagonal. Si \(A\) posee algún autovalor complejo, en la diagonal apareceran bloques de tamaño \(2x2\) que contendrán los autovalores complejos conjugados.
Para ilustrar esto último, aunque no sea el caso que vamos a estudiar, veamos que ocurre si particularizamos al caso de una matriz \(A \in \mathbb{R}^{4x4}\) con dos autovalores reales y un par de complejos conjugados, la forma de Schur será: \(A = QTQ^{-1}\) con,
Y los autovalores son: \(\lambda_1, \lambda_2, \lambda_{3,4}= a\pm \sqrt{cb}\).
Veamos un ejemplos:
cuyos autovalores son \(\lambda_1 = 3, \lambda_2= -1, \lambda_3= 2+3i,\lambda_4= 2-3i\). La descomposición de Schur de la matriz es:
# Matriz real
A = np.array([[1.,2., 0., 0.],[2., 1., 0., 0.],[0., 0., 2., -3.],[0., 0., 3., 2.]])
#print(tabulate(A))
print(tabulate(A))
values,vect = np.linalg.eig(A)
print(f'Autovalores: {values}')
T,Q = sp.schur(A)
print(f'T= \n {tabulate(T)}')
print(f'Q= \n {tabulate(Q)}')
print(f'Q^-1TQ = \n {tabulate(Q@T@Q.T)}')
- - - --
1 2 0 0
2 1 0 0
0 0 2 -3
0 0 3 2
- - - --
Autovalores: [ 3.+0.j -1.+0.j 2.+3.j 2.-3.j]
T=
- -- - --
3 0 0 0
0 -1 0 0
0 0 2 -3
0 0 3 2
- -- - --
Q=
-------- --------- - -
0.707107 -0.707107 0 0
0.707107 0.707107 0 0
0 0 1 0
0 0 0 1
-------- --------- - -
Q^-1TQ =
- - - --
1 2 0 0
2 1 0 0
0 0 2 -3
0 0 3 2
- - - --
Si nos centramos en el caso que vamos a ver este curso con la matriz \(A\) real y simétrica, la matriz \(T\) en la descomposición de Schur toma forma diagonal.
A = np.array([[1, 2, 3], [2, 5, 0], [3, 0, 5]])
print(tabulate(A))
values,vect = np.linalg.eig(A)
print(f'Autovalores: {values}')
T,Q = sp.schur(A)
print(f'T= \n {tabulate(T)}')
print(f'Q= \n {tabulate(Q)}')
print(f'Q^-1TQ = \n {tabulate(Q@T@Q.T)}')
- - -
1 2 3
2 5 0
3 0 5
- - -
Autovalores: [-1.12310563 7.12310563 5. ]
T=
-------- ----------- -----------
-1.12311 8.88178e-16 6.79962e-17
0 7.12311 9.90683e-16
0 0 5
-------- ----------- -----------
Q=
--------- -------- --------
-0.861705 0.507409 0
0.28146 0.477988 -0.83205
0.42219 0.716982 0.5547
--------- -------- --------
Q^-1TQ =
- ------------ -----------
1 2 3
2 5 8.28753e-16
3 -2.18176e-16 5
- ------------ -----------
El algoritmo QR calcula el espectro completo de la matriz \(A\) encontrando una forma semejante de \(A\) a través de la transformación de Schur. Para ello utiliza un proceso iterativo. La idea básica es, en cada iteración, hacer una descomposición QR de la matriz original, construir una nueva matriz como el producto de los factores de la descomposición cambiados de orden y repetir hasta la convergencia:
Veamos paso a paso que ocurre en este proceso iterativo:
De la proposición 2 podemos concluir que \(Q = Q_0Q_1Q_2 \dots Q_k \) es una matriz ortogonal y que \(Q^{-1} = Q_k^{-1} \dots Q_2^{-1}Q_1^{-1}Q_0^{-1}\) es su inversa. Por tanto $\( A_k = Q^{-1}AQ = QAQ^{T} \)\(
<br>
Eso implica que \)A_k\( y \)A$ son semejantes y por tanto tienen los mismos autovalores.
Lo que no hemos demostrado (ni vamos a hacerlo en el caso general) es que este proceso iterativo termine con \(A_k\) triangular, o quasi-triangular en el caso de autovalores complejos. Sirva como argumento intuitivo la proximidad con el algoritmo de iteración simultánea en el caso de empezar con una matriz real y simétrica. Si la matriz es real y simétrica ambos algoritmos son equivalentes. El algoritmo QR convergerá a una forma de Schur donde T es diagonal y contendrá a los autovalores. Recordad que en el método de Iteración Simultánea aplicabamos el coeficiente de Rayleigh a las columnas de la matriz \(Q\) (autovectores) para obtener los autovalores.
Vamos a verlo con una versión no completa de ambos algoritmos. Nos detendremos al final del proceso iterativo y compararemos las matrices que ambos algoritmos generan.
def QR_algorithm_init(A):
Q = np.zeros_like(A)
R = np.zeros_like(A)
A_copy = A.copy()
for i in range(10000):
Q,R = np.linalg.qr(A_copy)
A_copy = np.matmul(R,Q)
return A_copy
def simultaneous_iteration_init(A):
Q = np.eye(A.shape[0])
eigenvalue = np.zeros(A.shape[1])
for i in range(10000):
Z = np.matmul(A,Q)
Q,R = np.linalg.qr(Z)
return Q.T@A@Q
A = np.array([[1, 2, 3], [2, 1, 3], [3, 3, 0]])
T = QR_algorithm_init(A)
print(f'T= \n {tabulate(T)}')
T = simultaneous_iteration_init(A)
print(f'T= \n {tabulate(T)}')
T=
------------ ------------ ------------
6 7.39727e-16 7.72993e-17
2.96439e-323 -3 7.55102e-17
0 0 -1
------------ ------------ ------------
T=
------------ ------------ ------------
6 -5.36945e-16 4.56224e-16
-5.75762e-16 -3 -1.68306e-16
4.34906e-16 -1.69181e-16 -1
------------ ------------ ------------
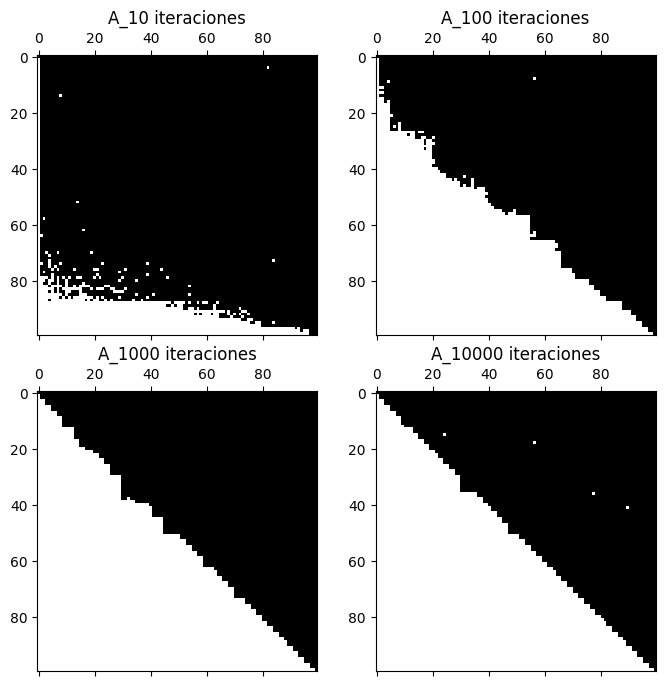
Ya vimos que el método de iteración simultanea solo funciona cuando los autovectores son ortogonales entre sí. En cambio el método QR es válido para todo tipo de matrices. La clave es la convergencia de \(A_k\) a una matriz \(T\) quasi-triangular. A modo ilustrativo veremos como se produce esa convergencia. Partiremos de una matriz aleatoria de tamaño \(100\times100\) e iremos aplicando el algoritmo QR. Cada cierto número de iteraciones comprobaremos la forma de la matriz \(A_k\)
import matplotlib.pyplot as plt
A = np.random.rand(100,100)
for i in range(10000):
Q,R = np.linalg.qr(A)
A = np.matmul(R,Q)
if i==10:
A10= A.copy()
elif i==100:
A100= A.copy()
elif i==1000:
A1000= A.copy()
elif i==9999:
A10000= A.copy()
fig, axs = plt.subplots(2, 2, figsize=(8, 8))
axs[0, 0].spy(abs(A10)>1e-4)
axs[0, 1].spy(abs(A100)>1e-4)
axs[1, 0].spy(abs(A1000)>1e-4)
axs[1, 1].spy(abs(A10000)>1e-4)
axs[0, 0].set_title('A_10 iteraciones')
axs[0, 1].set_title('A_100 iteraciones')
axs[1, 0].set_title('A_1000 iteraciones')
axs[1, 1].set_title('A_10000 iteraciones')
plt.show()
Ahora que nos creemos el algoritmo podemos completarlo para extraer los autovalores y autovectores.
El algoritmo QR convierte la matriz \(A\) en una triangular superior si todos sus autovalores son reales. Esta matriz triangular es semejante a \(A\) y por tanto sus autovalores, situados en la diagonal principal, son los mismos que los de \(A\).
El cálculo de los autovectores asociados se puede hacer resolviendo el sistema lineal \((A-\lambda I)\vec{v} = \bf{0}\) o aplicando el método de la potencia inversa a la matriz \(A-\lambda I\).
def QR_algorithm(A):
Q = np.zeros_like(A)
R = np.zeros_like(A)
eigvectors = np.zeros_like(A)
eigvalues = np.zeros(A.shape[0])
A_copy = A.copy()
for i in range(10000):
Q,R = QR_decomposition(A_copy)
#Q,R = np.linalg.qr(A_copy)
A_copy = np.matmul(R,Q)
# los autovalores están en la diagonal de A_copy
for i in range(A.shape[0]):
eigvalues[i], eigvectors[:,i] = potencia_inversa_shift(A, A_copy[i,i])
return eigvalues, eigvectors
Veamos cómo funciona con un par de ejemplos:
Matriz simétrica
cuyos autovalores son \(\lambda_1 = 3. ; \lambda_2 = -2.5141; \lambda_3 = 2.0861\) y \(\lambda_4 = -0.5720\).
Al aplicar el algoritmo QR, nos devuelve:
S = np.array([[-1.,0., 1., -1.],[0., 1., -2., 0],[1., -2., 0., 1],[-1., 0., 1., 2.]])
values,vect = QR_algorithm(S)
print(f'La matriz T de la forma de Schur de A es: \n {tabulate(QR_algorithm_init(S))}')
print('Autovalores QR: ',values)
for i in range(len(values)):
print(f'Autovector {i+1}: {vect[:,i]}')
La matriz T de la forma de Schur de A es:
------------- ------------- ----------- ------------
3 2.5133e-16 1.17967e-16 -1.04356e-15
-4.94066e-323 -2.51414 1.57931e-15 -2.85943e-16
1.97626e-323 6.42285e-323 2.08613 4.79185e-16
0 0 0 -0.571993
------------- ------------- ----------- ------------
Autovalores QR: [ 3. -2.51413693 2.0861302 -0.57199327]
Autovector 1: [-8.36901078e-15 5.77350269e-01 -5.77350269e-01 -5.77350269e-01]
Autovector 2: [-0.6096698 0.36717314 0.64514835 -0.27797521]
Autovector 3: [-0.332506 0.49189489 -0.26713095 0.75902584]
Autovector 4: [0.71954325 0.5384143 0.42319183 0.11522247]
Se puede ver que la matriz T en la forma de Schur \(A = QTQ^T\) es una matriz diagonal como era de esperar.
Veamos un ejemplo no simétrico:
Matriz no simétrica
cuyos autovalores son \(\lambda_1 = 2.6180 ; \lambda_2 = 2; \lambda_3 = -1\) y \(\lambda_4 = 0.3819\).
En este caso la matriz T en la forma de Schur \(A = QTQ^T\) no es una matriz diagonal pero sí triangular superior.
S = np.array([[3.,2., -1., 1.],[0., -1., 0., 0],[1, 0.3, 2., 0],[0., 1., 2., 0.]])
values,vect = QR_algorithm(S)
print(f'La matriz T de la forma de Schur de A es: \n {tabulate(QR_algorithm_init(S))}')
print('Autovalores QR: ',values)
for i in range(len(values)):
print(f'Autovector {i+1}: {vect[:,i]}')
T,Q = sp.schur(S)
print(f'T= \n {tabulate(T)}')
print(f'Q= \n {tabulate(Q)}')
print(f'Q^-1TQ = \n {tabulate(Q@T@Q.T)}')
---------------------------------------------------------------------------
LinAlgError Traceback (most recent call last)
Cell In[25], line 2
1 S = np.array([[3.,2., -1., 1.],[0., -1., 0., 0],[1, 0.3, 2., 0],[0., 1., 2., 0.]])
----> 2 values,vect = QR_algorithm(S)
3 print(f'La matriz T de la forma de Schur de A es: \n {tabulate(QR_algorithm_init(S))}')
4 print('Autovalores QR: ',values)
Cell In[23], line 13, in QR_algorithm(A)
11 # los autovalores están en la diagonal de A_copy
12 for i in range(A.shape[0]):
---> 13 eigvalues[i], eigvectors[:,i] = potencia_inversa_shift(A, A_copy[i,i])
14 return eigvalues, eigvectors
Cell In[10], line 15, in potencia_inversa_shift(A, beta)
12 while not convergencia:
13 #Resuelvo los dos sistemas lineales triangulares
14 y = sp.solve_triangular(L, np.matmul(P,x), lower=True)
---> 15 x1 = sp.solve_triangular(U, y, lower=False)
17 x1 = x1/norm2(x1)
18 eigvalue1 = np.dot(x1,np.matmul(A,x1)) # Aproximación del autovalor asociado al autovector menos dominante usando A
File /opt/hostedtoolcache/Python/3.10.13/x64/lib/python3.10/site-packages/scipy/linalg/_basic.py:356, in solve_triangular(a, b, trans, lower, unit_diagonal, overwrite_b, check_finite)
354 return x
355 if info > 0:
--> 356 raise LinAlgError("singular matrix: resolution failed at diagonal %d" %
357 (info-1))
358 raise ValueError('illegal value in %dth argument of internal trtrs' %
359 (-info))
LinAlgError: singular matrix: resolution failed at diagonal 3